搜索到
126
篇与
的结果
-
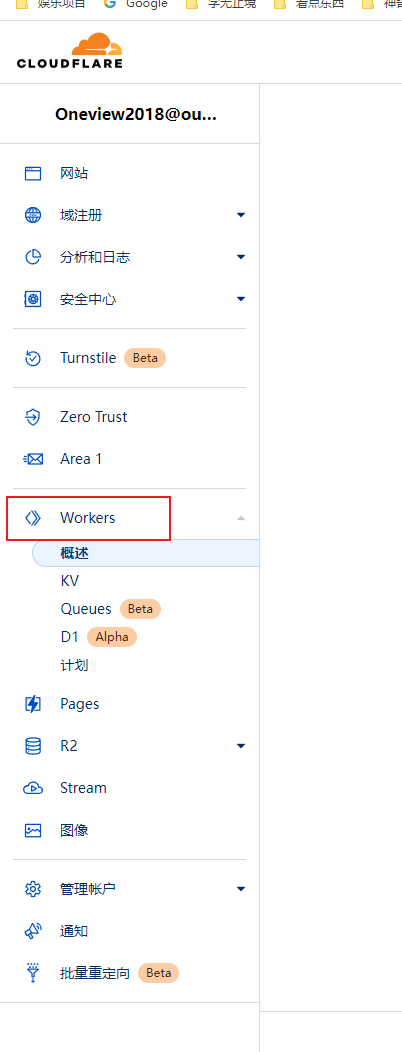
![使用CloudFlare制作镜像加速站如Github]() 使用CloudFlare制作镜像加速站如Github 这里以Github举例登录Cloudflare点击左侧的Workers,创建一个服务,选择默认的Http处理程序即可点击快速编辑,复制代码保存到左侧编辑框,然后点保存并部署// 要代理的网站,这里用github举例 const upstream = 'raw.githubusercontent.com' // 要代理的网站移动版,可以和上面网站一样 const upstream_mobile = 'raw.githubusercontent.com' // 访问区域黑名单(按需设置). const blocked_region = [] // IP地址黑名单(按需设置). const blocked_ip_address = ['0.0.0.0', '127.0.0.1'] // 路径替换. const replace_dict = { '$upstream': '$custom_domain', '//archiveofourown.org': '' } addEventListener('fetch', event => { event.respondWith(fetchAndApply(event.request)); }) async function fetchAndApply(request) { const ip_address = request.headers.get('cf-connecting-ip'); const user_agent = request.headers.get('user-agent'); let response = null; let url = new URL(request.url); let url_host = url.host; if (url.protocol == 'http:') { url.protocol = 'https:' response = Response.redirect(url.href); return response; } if (await device_status(user_agent)) { var upstream_domain = upstream; } else { var upstream_domain = upstream_mobile; } url.host = upstream_domain; if(blocked_ip_address.includes(ip_address)){ response = new Response('Access denied: Your IP address is blocked by WorkersProxy.', { status: 403 }); } else{ let method = request.method; let request_headers = request.headers; let new_request_headers = new Headers(request_headers); new_request_headers.set('Host', upstream_domain); new_request_headers.set('Referer', url.href); let original_response = await fetch(url.href, { method: method, headers: new_request_headers }) let original_response_clone = original_response.clone(); let original_text = null; let response_headers = original_response.headers; let new_response_headers = new Headers(response_headers); let status = original_response.status; new_response_headers.set('cache-control' ,'public, max-age=14400') new_response_headers.set('access-control-allow-origin', '*'); new_response_headers.set('access-control-allow-credentials', true); new_response_headers.delete('content-security-policy'); new_response_headers.delete('content-security-policy-report-only'); new_response_headers.delete('clear-site-data'); const content_type = new_response_headers.get('content-type'); if (content_type.includes('text/html') && content_type.includes('UTF-8')) { original_text = await replace_response_text(original_response_clone, upstream_domain, url_host); } else { original_text = original_response_clone.body } response = new Response(original_text, { status, headers: new_response_headers }) } return response; } async function replace_response_text(response, upstream_domain, host_name) { let text = await response.text() var i, j; for (i in replace_dict) { j = replace_dict[i] if (i == '$upstream') { i = upstream_domain } else if (i == '$custom_domain') { i = host_name } if (j == '$upstream') { j = upstream_domain } else if (j == '$custom_domain') { j = host_name } let re = new RegExp(i, 'g') text = text.replace(re, j); } return text; } async function device_status (user_agent_info) { var agents = ["Android", "iPhone", "SymbianOS", "Windows Phone", "iPad", "iPod"]; var flag = true; for (var v = 0; v < agents.length; v++) { if (user_agent_info.indexOf(agents[v]) > 0) { flag = false; break; } } return flag; }然后打开链接就可以代理访问了如果需要自定义域名,直接把域名的CNAME解析到你得链接就可以。或者点击触发器,添加自定义域就可以
使用CloudFlare制作镜像加速站如Github 这里以Github举例登录Cloudflare点击左侧的Workers,创建一个服务,选择默认的Http处理程序即可点击快速编辑,复制代码保存到左侧编辑框,然后点保存并部署// 要代理的网站,这里用github举例 const upstream = 'raw.githubusercontent.com' // 要代理的网站移动版,可以和上面网站一样 const upstream_mobile = 'raw.githubusercontent.com' // 访问区域黑名单(按需设置). const blocked_region = [] // IP地址黑名单(按需设置). const blocked_ip_address = ['0.0.0.0', '127.0.0.1'] // 路径替换. const replace_dict = { '$upstream': '$custom_domain', '//archiveofourown.org': '' } addEventListener('fetch', event => { event.respondWith(fetchAndApply(event.request)); }) async function fetchAndApply(request) { const ip_address = request.headers.get('cf-connecting-ip'); const user_agent = request.headers.get('user-agent'); let response = null; let url = new URL(request.url); let url_host = url.host; if (url.protocol == 'http:') { url.protocol = 'https:' response = Response.redirect(url.href); return response; } if (await device_status(user_agent)) { var upstream_domain = upstream; } else { var upstream_domain = upstream_mobile; } url.host = upstream_domain; if(blocked_ip_address.includes(ip_address)){ response = new Response('Access denied: Your IP address is blocked by WorkersProxy.', { status: 403 }); } else{ let method = request.method; let request_headers = request.headers; let new_request_headers = new Headers(request_headers); new_request_headers.set('Host', upstream_domain); new_request_headers.set('Referer', url.href); let original_response = await fetch(url.href, { method: method, headers: new_request_headers }) let original_response_clone = original_response.clone(); let original_text = null; let response_headers = original_response.headers; let new_response_headers = new Headers(response_headers); let status = original_response.status; new_response_headers.set('cache-control' ,'public, max-age=14400') new_response_headers.set('access-control-allow-origin', '*'); new_response_headers.set('access-control-allow-credentials', true); new_response_headers.delete('content-security-policy'); new_response_headers.delete('content-security-policy-report-only'); new_response_headers.delete('clear-site-data'); const content_type = new_response_headers.get('content-type'); if (content_type.includes('text/html') && content_type.includes('UTF-8')) { original_text = await replace_response_text(original_response_clone, upstream_domain, url_host); } else { original_text = original_response_clone.body } response = new Response(original_text, { status, headers: new_response_headers }) } return response; } async function replace_response_text(response, upstream_domain, host_name) { let text = await response.text() var i, j; for (i in replace_dict) { j = replace_dict[i] if (i == '$upstream') { i = upstream_domain } else if (i == '$custom_domain') { i = host_name } if (j == '$upstream') { j = upstream_domain } else if (j == '$custom_domain') { j = host_name } let re = new RegExp(i, 'g') text = text.replace(re, j); } return text; } async function device_status (user_agent_info) { var agents = ["Android", "iPhone", "SymbianOS", "Windows Phone", "iPad", "iPod"]; var flag = true; for (var v = 0; v < agents.length; v++) { if (user_agent_info.indexOf(agents[v]) > 0) { flag = false; break; } } return flag; }然后打开链接就可以代理访问了如果需要自定义域名,直接把域名的CNAME解析到你得链接就可以。或者点击触发器,添加自定义域就可以 -
![给Thinkphp3用上composer]() 给Thinkphp3用上composer 都2021年了,我不理解为什么还要使用TP3的项目修改系统构建时使用的是 thinkphp3.2.3,当时的框架并没有使用 composer 作为包管理器,第三方包统一放到了 ThinkPHP/Library/Vendor 目录下面。随着第三方包越来越多,单纯的使用 vendor() 加载扩展已经没法满足要求,所以记录下tp3使用composer的过程1. 项目根目录添加 composer.json{ "require": { "zircote/swagger-php": "^2.0", "giggsey/libphonenumber-for-php": "^8.12" }, "repositories": { "packagist": { "type": "composer", "url": "https://mirrors.aliyun.com/composer/" } } }2. 安装composer安装composer看这个:安装composer3. 安装依赖项目目录直接安装依赖包,自动生成 vendor 目录composer install4. 引入自动加载在原来的 thinphp 框架里 index.php 文件头部首行引入 vendor/autoload.php<?php header('Access-Control-Allow-Origin:*'); // 增加自动加载 require './vendor/autoload.php'; if(version_compare(PHP_VERSION,'5.3.0','<')) die('require PHP > 5.3.0 !'); define('APP_DEBUG',true); define('APP_PATH','./Application/'); define('RUNTIME_PATH','./Runtime/');define("TMPL_PATH","./tpl/"); define("UPLOAD_PATH","./Upload/"); 完成
给Thinkphp3用上composer 都2021年了,我不理解为什么还要使用TP3的项目修改系统构建时使用的是 thinkphp3.2.3,当时的框架并没有使用 composer 作为包管理器,第三方包统一放到了 ThinkPHP/Library/Vendor 目录下面。随着第三方包越来越多,单纯的使用 vendor() 加载扩展已经没法满足要求,所以记录下tp3使用composer的过程1. 项目根目录添加 composer.json{ "require": { "zircote/swagger-php": "^2.0", "giggsey/libphonenumber-for-php": "^8.12" }, "repositories": { "packagist": { "type": "composer", "url": "https://mirrors.aliyun.com/composer/" } } }2. 安装composer安装composer看这个:安装composer3. 安装依赖项目目录直接安装依赖包,自动生成 vendor 目录composer install4. 引入自动加载在原来的 thinphp 框架里 index.php 文件头部首行引入 vendor/autoload.php<?php header('Access-Control-Allow-Origin:*'); // 增加自动加载 require './vendor/autoload.php'; if(version_compare(PHP_VERSION,'5.3.0','<')) die('require PHP > 5.3.0 !'); define('APP_DEBUG',true); define('APP_PATH','./Application/'); define('RUNTIME_PATH','./Runtime/');define("TMPL_PATH","./tpl/"); define("UPLOAD_PATH","./Upload/"); 完成 -
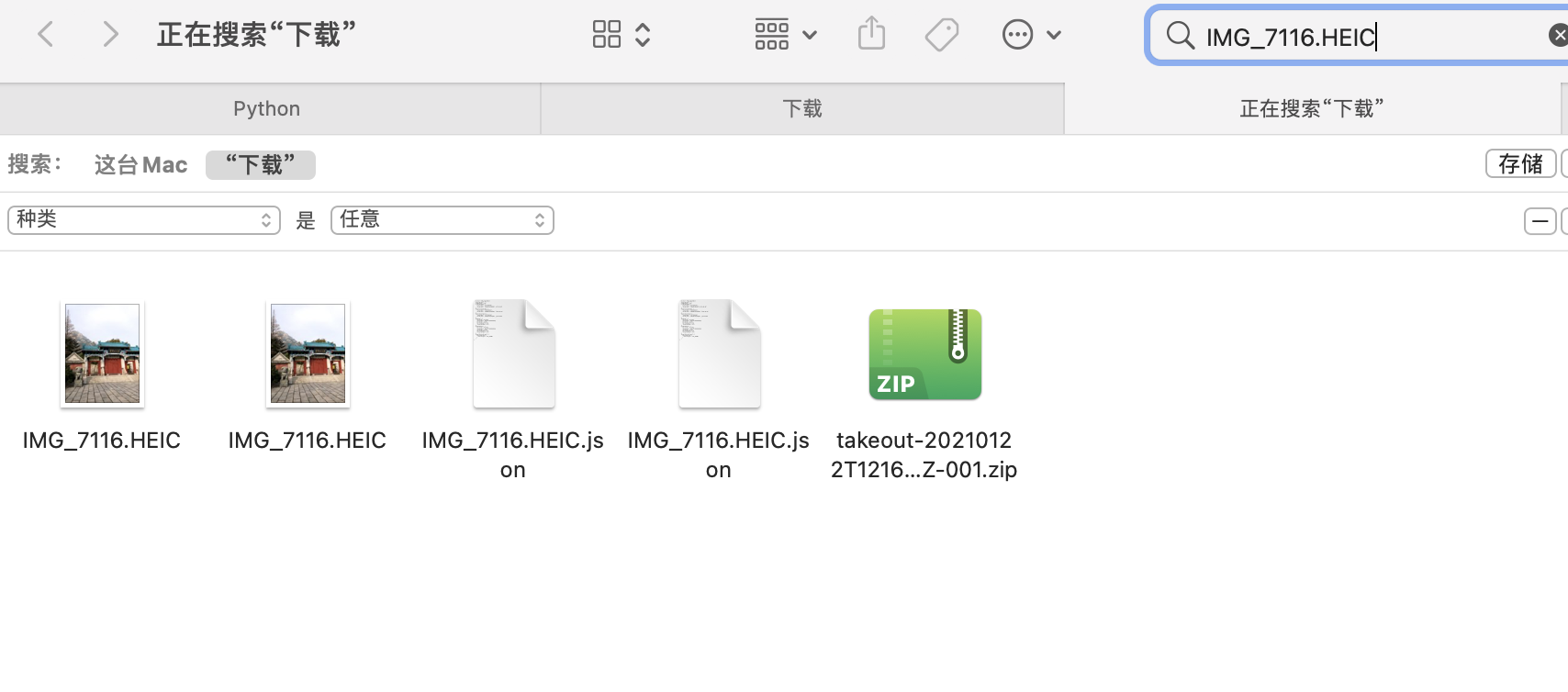
![Google相册元数据修复]() Google相册元数据修复 前提承接上一篇《如何批量导出Google相册所有数据》根据上一篇的方法导出的归档数据,往往许多信息都被抹除了,也就是Meta信息丢失,其中包括但不限于照片的定位信息(经纬度)、拍摄时间、拍照设备、光圈等一大堆信息。如果你默认下载了所有相册集,那么可能会有大量重复照片等着你,最可气的是如果你没有调整IOS设备的拍照格式的话,默认拍出的都是HEIC/HEVC格式的内容,而Google恰恰又把IOS设备默认的HEIC格式照片直接处理成了一个jpg加一个2到3秒左右的MOV短视频,如果你使用HEIC拍摄了大量照片,那可能只能一个个手动在相册选择删除。所以一般来讲,通过归档批量导出的数据,可能会遇到以下几种情况:Meta信息丢失重复时间混乱多出大量的短视频所以我一直在思考要如何处理这些问题。首先是Meta信息丢失,直接导致了我把照片直接导入相册后时间线混乱,可能我昨天拍的照片会出现在2007年那一栏中,其次往往许多照片旁边伴随着一个2秒短视频,相册一眼望过去全是重复内容,让人苦恼不堪。用Google search了一圈,发现网上有人提出问题,但是没人解决,痛定思痛,我决定写个小脚本批量处理,然后再导入手机。(最底下有完整代码,也已经放在Github上)最终实现了视频时长短于2s的,放在了under2文件夹下,短于3s的,全部放在了under3文件夹下重复文件默认被删除,包括.json和视频文件,如果代码中dealDuplicate(False),则会归类到Duplicate文件夹下根据所有.json文件修复了照片的Exif数据和日期HEIC格式相片统一放在了同名文件夹下json文件统一放在json文件夹里 脚本是python写的,没怎么用过这个语言,本着实用主义原则,代码可能并不优雅重复照片我仔细观察了一下,发现大量重复照片和视频的下载名称都相同,那就直接扫描文件夹,把重复文件剔除即可def dealDuplicate(delete=True): fileList = {} dg = os.walk(scanDir) for path,dir_list,file_list in dg: for file_name in file_list: full_file_name = os.path.join(path, file_name) if file_name == '元数据.json': continue #处理重复文件 if file_name in fileList.keys(): DupDir = scanDir + '/Duplicate/' if not os.path.exists(DupDir): os.makedirs(DupDir) if delete: os.remove(full_file_name) #这里可以直接删除 else: if not os.path.exists(DupDir + file_name): shutil.move(full_file_name, DupDir) print('重复文件:' + full_file_name + ' ------ ' + fileList[file_name]) else: fileList[file_name] = full_file_name fileList.clear()重复短视频另一个就是大量HEIC转换出来的大量短视频,都是.MOV格式文件,这里我选择通过ffmpeg判断视频时长,进而把时长在3s以内的视频过滤出来,最终全部删除有选择地分门别类。这里需要安装一下ffmpeg的扩展,pip3 install ffmpeg-python即可还有一点是需要提前安装好ffmepg可执行文件并配置好环境变量,否则有可能会报找不到ffprobe错误#文件分类 def dealClassify(): #部分文件变了,重新扫描 g = os.walk(scanDir) for path, dir_list, file_list in g: for file_name in file_list: full_file_name = os.path.join(path, file_name) #处理时长低于3s的视频 if os.path.splitext(file_name)[-1] == '.MOV': print('根据时长分类文件:' + full_file_name) info = ffmpeg.probe(full_file_name) #print(info) duration = info['format']['duration'] #时长 if float(duration) <= 2: under2Dir = scanDir + '/under2/' if not os.path.exists(under2Dir): print('创建文件夹:' + under2Dir) os.makedirs(under2Dir) if not os.path.exists(under2Dir + file_name): shutil.move(full_file_name, under2Dir) elif 2 < float(duration) <= 3: under3Dir = scanDir + '/under3/' if not os.path.exists(under3Dir): print('创建文件夹:' + under3Dir) os.makedirs(under3Dir) if not os.path.exists(under3Dir + file_name): shutil.move(full_file_name, under3Dir) #处理HEIC文件 elif os.path.splitext(file_name)[-1] == '.HEIC': heicDir = scanDir + '/HEIC/' if not os.path.exists(heicDir): os.makedirs(heicDir) if not os.path.exists(heicDir + file_name): shutil.move(full_file_name, heicDir) #单独存储json文件 elif os.path.splitext(file_name)[-1] == '.json': jsonDir = scanDir + '/json/' if not os.path.exists(jsonDir): os.makedirs(jsonDir) if not os.path.exists(jsonDir + file_name): shutil.move(full_file_name, jsonDir) #print('处理json文件:' + full_file_name) #print('json文件:' + os.path.splitext(file_name)[-2] + '.json')这里顺便筛选剔除了HEIC格式的照片,并把所有json文件单独放到一个文件夹备用修复Exif数据谷歌把每一张照片原本的 Exif 数据(e.g. 地点、日期)抹掉,然后提取出来放到了对应的 JSON 里,另外目前版本看到的格式只有xx.扩展和xx.文件扩展.json这种命名方式的Meta文件,其他格式命名的没有做处理。我这里的格式大概如下:{ "title": "IMG_4093.jpg", "description": "", "imageViews": "0", "creationTime": { "timestamp": "1525150106", "formatted": "2018年5月1日UTC 上午4:48:26" }, "modificationTime": { "timestamp": "1607202343", "formatted": "2020年12月5日UTC 下午9:05:43" }, "photoTakenTime": { "timestamp": "1485071348", "formatted": "2017年1月22日UTC 上午7:49:08" }, "geoData": { "latitude": 34.18444722222222, "longitude": 116.92279722222223, "altitude": 48.648960739030024, "latitudeSpan": 0.0, "longitudeSpan": 0.0 }, "geoDataExif": { "latitude": 34.18444722222222, "longitude": 116.92279722222223, "altitude": 48.648960739030024, "latitudeSpan": 0.0, "longitudeSpan": 0.0 }, "googlePhotosOrigin": { "mobileUpload": { "deviceType": "IOS_PHONE" } } }导出的文件中有部分是不存在.json元数据的,有些照片我的 Exif 丢了,有些照片则没丢,不清楚是否和勾选原图上传有关,所以脚本里要提前判断。我这里用了piexif和PIL库,安装方式pip3 install piexif,pip3 install Pillow。#计算lat/lng信息 def format_latlng(latlng): degree = int(latlng) res_degree = latlng - degree minute = int(res_degree * 60) res_minute = res_degree * 60 - minute seconds = round(res_minute * 60.0,3) return ((degree, 1), (minute, 1), (int(seconds * 1000), 1000)) #读json def readJson(json_file): with open(json_file, 'r') as load_f: return json.load(load_f) #处理照片exif信息 def dealExif(): g = os.walk(scanDir) for path,dir_list,file_list in g: for file_name in file_list: full_file_name = os.path.join(path, file_name) ext_name = os.path.splitext(file_name)[-1] if ext_name.lower() in ['.jpg','.jpeg','.png']: # if file_name != 'ee7db1e41afc9fd342e42e0a5034006b.JPG': # 单文件测试 # continue if not os.path.exists(scanDir + '/json/' + file_name + '.json'): continue exifJson = readJson(scanDir + '/json/' + file_name + '.json') print('处理Exif:' + full_file_name) try: img = Image.open(full_file_name) # 读图 exif_dict = piexif.load(img.info['exif']) except UnidentifiedImageError: print("图片读取失败:" + full_file_name) continue except KeyError: print("图片没有exif数据,尝试创建:" + full_file_name) exif_dict = {'0th':{},'Exif': {},'GPS': {}} # 修改exif数据 exif_dict['0th'][piexif.ImageIFD.DateTime] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['photoTakenTime']['timestamp']))).encode('utf-8') exif_dict['Exif'][piexif.ExifIFD.DateTimeOriginal] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['creationTime']['timestamp']))).encode('utf-8') exif_dict['Exif'][piexif.ExifIFD.DateTimeDigitized] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['modificationTime']['timestamp']))).encode('utf-8') exif_dict['GPS'][piexif.GPSIFD.GPSLatitude] = format_latlng(exifJson['geoDataExif']['latitude']) exif_dict['GPS'][piexif.GPSIFD.GPSLongitude] = format_latlng(exifJson['geoDataExif']['longitude']) # exif_dict['GPS'][piexif.GPSIFD.GPSLongitudeRef] = 'W' # exif_dict['GPS'][piexif.GPSIFD.GPSLatitudeRef] = 'N' exif_bytes = piexif.dump(exif_dict) img.save(full_file_name, None, exif=exif_bytes) #修改文件时间(可选) # photoTakenTime = time.strftime("%Y%m%d%H%M.%S", time.localtime(int(exifJson['photoTakenTime']['timestamp']))) # os.system('touch -t "{}" "{}"'.format(photoTakenTime, full_file_name)) # os.system('touch -mt "{}" "{}"'.format(photoTakenTime, full_file_name)) 修改下对应路径依次运行即可if __name__ == '__main__': scanDir = r'/Users/XXX/Downloads/Takeout' #TODO 这里修改归档的解压目录 dealDuplicate() dealClassify() dealExif() print('终于搞完了,Google Photos 辣鸡')总结7K多个照片视频运行了大概2分钟跑完了,最终运行一遍下来之后,多余的照片和视频已经处理掉了,那些HEIC已经被分成JPG+MOV的,程序把MOV视频剔除,所有照片已有的Exif已经修复了,代码中有一段修改文件时间的被我注释了,有条件的可以参考各自系统修改下文件时间就更好了。把一路运行下来的坑都踩了一遍,如果有什么问题我再补充好了。完整代码!注意是Python3环境也可以直接在Github上查看#!/usr/bin/python3 # -*- coding:utf-8 -*- # @Author : gty0211@foxmail.com import json import os import shutil import time import ffmpeg import piexif from PIL import Image, UnidentifiedImageError #归档zip解压目录 scanDir = '' #处理重复 def dealDuplicate(delete=True): fileList = {} dg = os.walk(scanDir) for path,dir_list,file_list in dg: for file_name in file_list: full_file_name = os.path.join(path, file_name) if file_name == '元数据.json': continue #处理重复文件 if file_name in fileList.keys(): DupDir = scanDir + '/Duplicate/' if not os.path.exists(DupDir): os.makedirs(DupDir) if delete: os.remove(full_file_name) #这里可以直接删除 else: if not os.path.exists(DupDir + file_name): shutil.move(full_file_name, DupDir) print('重复文件:' + full_file_name + ' ------ ' + fileList[file_name]) else: fileList[file_name] = full_file_name fileList.clear() #文件分类 def dealClassify(): #部分文件变了,重新扫描 g = os.walk(scanDir) for path, dir_list, file_list in g: for file_name in file_list: full_file_name = os.path.join(path, file_name) #处理时长低于3s的视频 if os.path.splitext(file_name)[-1] == '.MOV': print('根据时长分类文件:' + full_file_name) info = ffmpeg.probe(full_file_name) #print(info) duration = info['format']['duration'] #时长 if float(duration) <= 2: under2Dir = scanDir + '/under2/' if not os.path.exists(under2Dir): print('创建文件夹:' + under2Dir) os.makedirs(under2Dir) if not os.path.exists(under2Dir + file_name): shutil.move(full_file_name, under2Dir) elif 2 < float(duration) <= 3: under3Dir = scanDir + '/under3/' if not os.path.exists(under3Dir): print('创建文件夹:' + under3Dir) os.makedirs(under3Dir) if not os.path.exists(under3Dir + file_name): shutil.move(full_file_name, under3Dir) #处理HEIC文件 elif os.path.splitext(file_name)[-1] == '.HEIC': heicDir = scanDir + '/HEIC/' if not os.path.exists(heicDir): os.makedirs(heicDir) if not os.path.exists(heicDir + file_name): shutil.move(full_file_name, heicDir) #单独存储json文件 elif os.path.splitext(file_name)[-1] == '.json': jsonDir = scanDir + '/json/' if not os.path.exists(jsonDir): os.makedirs(jsonDir) if not os.path.exists(jsonDir + file_name): shutil.move(full_file_name, jsonDir) #计算lat/lng信息 def format_latlng(latlng): degree = int(latlng) res_degree = latlng - degree minute = int(res_degree * 60) res_minute = res_degree * 60 - minute seconds = round(res_minute * 60.0,3) return ((degree, 1), (minute, 1), (int(seconds * 1000), 1000)) #读json def readJson(json_file): with open(json_file, 'r') as load_f: return json.load(load_f) #处理照片exif信息 def dealExif(): g = os.walk(scanDir) for path,dir_list,file_list in g: for file_name in file_list: full_file_name = os.path.join(path, file_name) ext_name = os.path.splitext(file_name)[-1] if ext_name.lower() in ['.jpg','.jpeg','.png']: # if file_name != 'ee7db1e41afc9fd342e42e0a5034006b.JPG': # 单文件测试 # continue if not os.path.exists(scanDir + '/json/' + file_name + '.json'): continue exifJson = readJson(scanDir + '/json/' + file_name + '.json') print('处理Exif:' + full_file_name) try: img = Image.open(full_file_name) # 读图 exif_dict = piexif.load(img.info['exif']) except UnidentifiedImageError: print("图片读取失败:" + full_file_name) continue except KeyError: print("图片没有exif数据,尝试创建:" + full_file_name) exif_dict = {'0th':{},'Exif': {},'GPS': {}} # 修改exif数据 exif_dict['0th'][piexif.ImageIFD.DateTime] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['photoTakenTime']['timestamp']))).encode('utf-8') exif_dict['Exif'][piexif.ExifIFD.DateTimeOriginal] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['creationTime']['timestamp']))).encode('utf-8') exif_dict['Exif'][piexif.ExifIFD.DateTimeDigitized] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['modificationTime']['timestamp']))).encode('utf-8') exif_dict['GPS'][piexif.GPSIFD.GPSLatitude] = format_latlng(exifJson['geoDataExif']['latitude']) exif_dict['GPS'][piexif.GPSIFD.GPSLongitude] = format_latlng(exifJson['geoDataExif']['longitude']) # exif_dict['GPS'][piexif.GPSIFD.GPSLongitudeRef] = 'W' # exif_dict['GPS'][piexif.GPSIFD.GPSLatitudeRef] = 'N' exif_bytes = piexif.dump(exif_dict) img.save(full_file_name, None, exif=exif_bytes) #修改文件时间(可选) # photoTakenTime = time.strftime("%Y%m%d%H%M.%S", time.localtime(int(exifJson['photoTakenTime']['timestamp']))) # os.system('touch -t "{}" "{}"'.format(photoTakenTime, full_file_name)) # os.system('touch -mt "{}" "{}"'.format(photoTakenTime, full_file_name)) if __name__ == '__main__': scanDir = r'/Users/XXX/Downloads/Takeout' #TODO 这里修改归档的解压目录 dealDuplicate() dealClassify() dealExif() print('终于搞完了,Google Photos 辣鸡')
Google相册元数据修复 前提承接上一篇《如何批量导出Google相册所有数据》根据上一篇的方法导出的归档数据,往往许多信息都被抹除了,也就是Meta信息丢失,其中包括但不限于照片的定位信息(经纬度)、拍摄时间、拍照设备、光圈等一大堆信息。如果你默认下载了所有相册集,那么可能会有大量重复照片等着你,最可气的是如果你没有调整IOS设备的拍照格式的话,默认拍出的都是HEIC/HEVC格式的内容,而Google恰恰又把IOS设备默认的HEIC格式照片直接处理成了一个jpg加一个2到3秒左右的MOV短视频,如果你使用HEIC拍摄了大量照片,那可能只能一个个手动在相册选择删除。所以一般来讲,通过归档批量导出的数据,可能会遇到以下几种情况:Meta信息丢失重复时间混乱多出大量的短视频所以我一直在思考要如何处理这些问题。首先是Meta信息丢失,直接导致了我把照片直接导入相册后时间线混乱,可能我昨天拍的照片会出现在2007年那一栏中,其次往往许多照片旁边伴随着一个2秒短视频,相册一眼望过去全是重复内容,让人苦恼不堪。用Google search了一圈,发现网上有人提出问题,但是没人解决,痛定思痛,我决定写个小脚本批量处理,然后再导入手机。(最底下有完整代码,也已经放在Github上)最终实现了视频时长短于2s的,放在了under2文件夹下,短于3s的,全部放在了under3文件夹下重复文件默认被删除,包括.json和视频文件,如果代码中dealDuplicate(False),则会归类到Duplicate文件夹下根据所有.json文件修复了照片的Exif数据和日期HEIC格式相片统一放在了同名文件夹下json文件统一放在json文件夹里 脚本是python写的,没怎么用过这个语言,本着实用主义原则,代码可能并不优雅重复照片我仔细观察了一下,发现大量重复照片和视频的下载名称都相同,那就直接扫描文件夹,把重复文件剔除即可def dealDuplicate(delete=True): fileList = {} dg = os.walk(scanDir) for path,dir_list,file_list in dg: for file_name in file_list: full_file_name = os.path.join(path, file_name) if file_name == '元数据.json': continue #处理重复文件 if file_name in fileList.keys(): DupDir = scanDir + '/Duplicate/' if not os.path.exists(DupDir): os.makedirs(DupDir) if delete: os.remove(full_file_name) #这里可以直接删除 else: if not os.path.exists(DupDir + file_name): shutil.move(full_file_name, DupDir) print('重复文件:' + full_file_name + ' ------ ' + fileList[file_name]) else: fileList[file_name] = full_file_name fileList.clear()重复短视频另一个就是大量HEIC转换出来的大量短视频,都是.MOV格式文件,这里我选择通过ffmpeg判断视频时长,进而把时长在3s以内的视频过滤出来,最终全部删除有选择地分门别类。这里需要安装一下ffmpeg的扩展,pip3 install ffmpeg-python即可还有一点是需要提前安装好ffmepg可执行文件并配置好环境变量,否则有可能会报找不到ffprobe错误#文件分类 def dealClassify(): #部分文件变了,重新扫描 g = os.walk(scanDir) for path, dir_list, file_list in g: for file_name in file_list: full_file_name = os.path.join(path, file_name) #处理时长低于3s的视频 if os.path.splitext(file_name)[-1] == '.MOV': print('根据时长分类文件:' + full_file_name) info = ffmpeg.probe(full_file_name) #print(info) duration = info['format']['duration'] #时长 if float(duration) <= 2: under2Dir = scanDir + '/under2/' if not os.path.exists(under2Dir): print('创建文件夹:' + under2Dir) os.makedirs(under2Dir) if not os.path.exists(under2Dir + file_name): shutil.move(full_file_name, under2Dir) elif 2 < float(duration) <= 3: under3Dir = scanDir + '/under3/' if not os.path.exists(under3Dir): print('创建文件夹:' + under3Dir) os.makedirs(under3Dir) if not os.path.exists(under3Dir + file_name): shutil.move(full_file_name, under3Dir) #处理HEIC文件 elif os.path.splitext(file_name)[-1] == '.HEIC': heicDir = scanDir + '/HEIC/' if not os.path.exists(heicDir): os.makedirs(heicDir) if not os.path.exists(heicDir + file_name): shutil.move(full_file_name, heicDir) #单独存储json文件 elif os.path.splitext(file_name)[-1] == '.json': jsonDir = scanDir + '/json/' if not os.path.exists(jsonDir): os.makedirs(jsonDir) if not os.path.exists(jsonDir + file_name): shutil.move(full_file_name, jsonDir) #print('处理json文件:' + full_file_name) #print('json文件:' + os.path.splitext(file_name)[-2] + '.json')这里顺便筛选剔除了HEIC格式的照片,并把所有json文件单独放到一个文件夹备用修复Exif数据谷歌把每一张照片原本的 Exif 数据(e.g. 地点、日期)抹掉,然后提取出来放到了对应的 JSON 里,另外目前版本看到的格式只有xx.扩展和xx.文件扩展.json这种命名方式的Meta文件,其他格式命名的没有做处理。我这里的格式大概如下:{ "title": "IMG_4093.jpg", "description": "", "imageViews": "0", "creationTime": { "timestamp": "1525150106", "formatted": "2018年5月1日UTC 上午4:48:26" }, "modificationTime": { "timestamp": "1607202343", "formatted": "2020年12月5日UTC 下午9:05:43" }, "photoTakenTime": { "timestamp": "1485071348", "formatted": "2017年1月22日UTC 上午7:49:08" }, "geoData": { "latitude": 34.18444722222222, "longitude": 116.92279722222223, "altitude": 48.648960739030024, "latitudeSpan": 0.0, "longitudeSpan": 0.0 }, "geoDataExif": { "latitude": 34.18444722222222, "longitude": 116.92279722222223, "altitude": 48.648960739030024, "latitudeSpan": 0.0, "longitudeSpan": 0.0 }, "googlePhotosOrigin": { "mobileUpload": { "deviceType": "IOS_PHONE" } } }导出的文件中有部分是不存在.json元数据的,有些照片我的 Exif 丢了,有些照片则没丢,不清楚是否和勾选原图上传有关,所以脚本里要提前判断。我这里用了piexif和PIL库,安装方式pip3 install piexif,pip3 install Pillow。#计算lat/lng信息 def format_latlng(latlng): degree = int(latlng) res_degree = latlng - degree minute = int(res_degree * 60) res_minute = res_degree * 60 - minute seconds = round(res_minute * 60.0,3) return ((degree, 1), (minute, 1), (int(seconds * 1000), 1000)) #读json def readJson(json_file): with open(json_file, 'r') as load_f: return json.load(load_f) #处理照片exif信息 def dealExif(): g = os.walk(scanDir) for path,dir_list,file_list in g: for file_name in file_list: full_file_name = os.path.join(path, file_name) ext_name = os.path.splitext(file_name)[-1] if ext_name.lower() in ['.jpg','.jpeg','.png']: # if file_name != 'ee7db1e41afc9fd342e42e0a5034006b.JPG': # 单文件测试 # continue if not os.path.exists(scanDir + '/json/' + file_name + '.json'): continue exifJson = readJson(scanDir + '/json/' + file_name + '.json') print('处理Exif:' + full_file_name) try: img = Image.open(full_file_name) # 读图 exif_dict = piexif.load(img.info['exif']) except UnidentifiedImageError: print("图片读取失败:" + full_file_name) continue except KeyError: print("图片没有exif数据,尝试创建:" + full_file_name) exif_dict = {'0th':{},'Exif': {},'GPS': {}} # 修改exif数据 exif_dict['0th'][piexif.ImageIFD.DateTime] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['photoTakenTime']['timestamp']))).encode('utf-8') exif_dict['Exif'][piexif.ExifIFD.DateTimeOriginal] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['creationTime']['timestamp']))).encode('utf-8') exif_dict['Exif'][piexif.ExifIFD.DateTimeDigitized] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['modificationTime']['timestamp']))).encode('utf-8') exif_dict['GPS'][piexif.GPSIFD.GPSLatitude] = format_latlng(exifJson['geoDataExif']['latitude']) exif_dict['GPS'][piexif.GPSIFD.GPSLongitude] = format_latlng(exifJson['geoDataExif']['longitude']) # exif_dict['GPS'][piexif.GPSIFD.GPSLongitudeRef] = 'W' # exif_dict['GPS'][piexif.GPSIFD.GPSLatitudeRef] = 'N' exif_bytes = piexif.dump(exif_dict) img.save(full_file_name, None, exif=exif_bytes) #修改文件时间(可选) # photoTakenTime = time.strftime("%Y%m%d%H%M.%S", time.localtime(int(exifJson['photoTakenTime']['timestamp']))) # os.system('touch -t "{}" "{}"'.format(photoTakenTime, full_file_name)) # os.system('touch -mt "{}" "{}"'.format(photoTakenTime, full_file_name)) 修改下对应路径依次运行即可if __name__ == '__main__': scanDir = r'/Users/XXX/Downloads/Takeout' #TODO 这里修改归档的解压目录 dealDuplicate() dealClassify() dealExif() print('终于搞完了,Google Photos 辣鸡')总结7K多个照片视频运行了大概2分钟跑完了,最终运行一遍下来之后,多余的照片和视频已经处理掉了,那些HEIC已经被分成JPG+MOV的,程序把MOV视频剔除,所有照片已有的Exif已经修复了,代码中有一段修改文件时间的被我注释了,有条件的可以参考各自系统修改下文件时间就更好了。把一路运行下来的坑都踩了一遍,如果有什么问题我再补充好了。完整代码!注意是Python3环境也可以直接在Github上查看#!/usr/bin/python3 # -*- coding:utf-8 -*- # @Author : gty0211@foxmail.com import json import os import shutil import time import ffmpeg import piexif from PIL import Image, UnidentifiedImageError #归档zip解压目录 scanDir = '' #处理重复 def dealDuplicate(delete=True): fileList = {} dg = os.walk(scanDir) for path,dir_list,file_list in dg: for file_name in file_list: full_file_name = os.path.join(path, file_name) if file_name == '元数据.json': continue #处理重复文件 if file_name in fileList.keys(): DupDir = scanDir + '/Duplicate/' if not os.path.exists(DupDir): os.makedirs(DupDir) if delete: os.remove(full_file_name) #这里可以直接删除 else: if not os.path.exists(DupDir + file_name): shutil.move(full_file_name, DupDir) print('重复文件:' + full_file_name + ' ------ ' + fileList[file_name]) else: fileList[file_name] = full_file_name fileList.clear() #文件分类 def dealClassify(): #部分文件变了,重新扫描 g = os.walk(scanDir) for path, dir_list, file_list in g: for file_name in file_list: full_file_name = os.path.join(path, file_name) #处理时长低于3s的视频 if os.path.splitext(file_name)[-1] == '.MOV': print('根据时长分类文件:' + full_file_name) info = ffmpeg.probe(full_file_name) #print(info) duration = info['format']['duration'] #时长 if float(duration) <= 2: under2Dir = scanDir + '/under2/' if not os.path.exists(under2Dir): print('创建文件夹:' + under2Dir) os.makedirs(under2Dir) if not os.path.exists(under2Dir + file_name): shutil.move(full_file_name, under2Dir) elif 2 < float(duration) <= 3: under3Dir = scanDir + '/under3/' if not os.path.exists(under3Dir): print('创建文件夹:' + under3Dir) os.makedirs(under3Dir) if not os.path.exists(under3Dir + file_name): shutil.move(full_file_name, under3Dir) #处理HEIC文件 elif os.path.splitext(file_name)[-1] == '.HEIC': heicDir = scanDir + '/HEIC/' if not os.path.exists(heicDir): os.makedirs(heicDir) if not os.path.exists(heicDir + file_name): shutil.move(full_file_name, heicDir) #单独存储json文件 elif os.path.splitext(file_name)[-1] == '.json': jsonDir = scanDir + '/json/' if not os.path.exists(jsonDir): os.makedirs(jsonDir) if not os.path.exists(jsonDir + file_name): shutil.move(full_file_name, jsonDir) #计算lat/lng信息 def format_latlng(latlng): degree = int(latlng) res_degree = latlng - degree minute = int(res_degree * 60) res_minute = res_degree * 60 - minute seconds = round(res_minute * 60.0,3) return ((degree, 1), (minute, 1), (int(seconds * 1000), 1000)) #读json def readJson(json_file): with open(json_file, 'r') as load_f: return json.load(load_f) #处理照片exif信息 def dealExif(): g = os.walk(scanDir) for path,dir_list,file_list in g: for file_name in file_list: full_file_name = os.path.join(path, file_name) ext_name = os.path.splitext(file_name)[-1] if ext_name.lower() in ['.jpg','.jpeg','.png']: # if file_name != 'ee7db1e41afc9fd342e42e0a5034006b.JPG': # 单文件测试 # continue if not os.path.exists(scanDir + '/json/' + file_name + '.json'): continue exifJson = readJson(scanDir + '/json/' + file_name + '.json') print('处理Exif:' + full_file_name) try: img = Image.open(full_file_name) # 读图 exif_dict = piexif.load(img.info['exif']) except UnidentifiedImageError: print("图片读取失败:" + full_file_name) continue except KeyError: print("图片没有exif数据,尝试创建:" + full_file_name) exif_dict = {'0th':{},'Exif': {},'GPS': {}} # 修改exif数据 exif_dict['0th'][piexif.ImageIFD.DateTime] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['photoTakenTime']['timestamp']))).encode('utf-8') exif_dict['Exif'][piexif.ExifIFD.DateTimeOriginal] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['creationTime']['timestamp']))).encode('utf-8') exif_dict['Exif'][piexif.ExifIFD.DateTimeDigitized] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( int(exifJson['modificationTime']['timestamp']))).encode('utf-8') exif_dict['GPS'][piexif.GPSIFD.GPSLatitude] = format_latlng(exifJson['geoDataExif']['latitude']) exif_dict['GPS'][piexif.GPSIFD.GPSLongitude] = format_latlng(exifJson['geoDataExif']['longitude']) # exif_dict['GPS'][piexif.GPSIFD.GPSLongitudeRef] = 'W' # exif_dict['GPS'][piexif.GPSIFD.GPSLatitudeRef] = 'N' exif_bytes = piexif.dump(exif_dict) img.save(full_file_name, None, exif=exif_bytes) #修改文件时间(可选) # photoTakenTime = time.strftime("%Y%m%d%H%M.%S", time.localtime(int(exifJson['photoTakenTime']['timestamp']))) # os.system('touch -t "{}" "{}"'.format(photoTakenTime, full_file_name)) # os.system('touch -mt "{}" "{}"'.format(photoTakenTime, full_file_name)) if __name__ == '__main__': scanDir = r'/Users/XXX/Downloads/Takeout' #TODO 这里修改归档的解压目录 dealDuplicate() dealClassify() dealExif() print('终于搞完了,Google Photos 辣鸡') -
![PHP一个简单字符串拼接签名的方法(Join)]() PHP一个简单字符串拼接签名的方法(Join) 经常有需求类似于:第一步:设所有发送或者接收到的数据为集合M,将集合M内非空参数值的参数按照参数名ASCII码从小到大排序(字典序),使用URL键值对的格式(即key1=value1&key2=value2…)拼接成字符串stringA。第二步:在stringA最后拼接上key得到stringSignTemp字符串,并对stringSignTemp进行MD5运算,再将得到的字符串所有字符转换为大写,得到sign值signValue。以往都是$k=$v&,最后再把末尾的&去掉,比较麻烦。无意间发现了有个join函数,用法如下:/** * 获取签名 * @param $params array 数组 * @return string 拼接后的字符串MD5 */ public function getSign($params) { ksort($params); $str = []; foreach ($params as $k => $v){ if (empty($v)) continue; $str[] = "{$k}={$v}"; } return strtoupper(md5(join('&',$str))); }
PHP一个简单字符串拼接签名的方法(Join) 经常有需求类似于:第一步:设所有发送或者接收到的数据为集合M,将集合M内非空参数值的参数按照参数名ASCII码从小到大排序(字典序),使用URL键值对的格式(即key1=value1&key2=value2…)拼接成字符串stringA。第二步:在stringA最后拼接上key得到stringSignTemp字符串,并对stringSignTemp进行MD5运算,再将得到的字符串所有字符转换为大写,得到sign值signValue。以往都是$k=$v&,最后再把末尾的&去掉,比较麻烦。无意间发现了有个join函数,用法如下:/** * 获取签名 * @param $params array 数组 * @return string 拼接后的字符串MD5 */ public function getSign($params) { ksort($params); $str = []; foreach ($params as $k => $v){ if (empty($v)) continue; $str[] = "{$k}={$v}"; } return strtoupper(md5(join('&',$str))); } -
![Python使用芝麻代理维护一个健康可用的IP池]() Python使用芝麻代理维护一个健康可用的IP池 最近有个需求要用Python做一个爬虫不间断运行,但是对方网站做了比较严格的反爬,然后就选择了用随机header和代理。刚开始的时候使用的免费代理,后来发现免费才是最贵的,经常失效或者连接不上,于是改为使用付费代理,最后选择了芝麻代理但是爬虫每秒请求可能为5QPS左右,芝麻代理默认请求为1QPS,所以只能采取维护一个代理池的方式,每次请求从中随机选取。刚开始的时候使用的是购买套餐,后来发现并不划算,套餐每天有使用上限,IP存活时间长的,上限数量就低,IP上限高的,存活时间又比较低,有预算上限的长时间爬虫类项目可以选择IP存活时间长的套餐,把维护IP池数量稍微降低一点,勉强够用一天了。不过后期还是建议使用按次购买,控制好频率就不怕超限。注意IP获取不计次,但是一旦使用就会计次之前没经验选择5分钟套餐,不到两点IP用量就要到上限了,选套餐还是建议存活时间长的这个维护IP池同时支持套餐和按次收费,所以也不用太过纠结首先你要获取到你的AppKey和Neek参数,在官网提取IP生成的API链接里可以获取到http://h.zhimaruanjian.com/getapi/#obtain_ip如果是选择的用套餐提取,还会有对应的pack参数,是你自己的对应套餐ID,在上面的链接同样可以获取到,然后实例化时把参数填进去即可。pack为0则按次提取IP这里我们按照维护大小为50个的IP池为例,使用示例如下:while True: try: begin = time.time() * 1000 zm = ZhiMaPool('You App Key', 'Your Neek') # 你的AppKey的Neek参数 zm.ip_sum = 50 # IP池总数量 # zm.pack = 121888 # 套餐pack参数,为0则使用按次提取,默认为0 # zm.ip_type = 'http' # http or https # zm.ttl = 60 # 过期提前失效时间,默认提前60秒 # zm.pool_path = './zhima_pool.json' # IP池保存路径 zm.check_ip() cost = time.time() * 1000 - begin print('本次耗时'+ str(cost) + '毫秒') time.sleep(30) # 间隔时间请少于ttl时长 except Exception as e: print(e)完整代码# -*- coding: utf-8 -*- # __author__ = "Yuuuu" gty0211@foxmail.com # Date: 2020-10-22 Python: 3.8 import os import time import requests import json import re class ZhiMaPool(object): pool_path = './zhima_pool.json' # IP池保存地址 ttl = 60 # 过期间隔 pack = 0 # 套餐pack参数,为0则使用按次提取 ip_pool = [] ip_type = 'http' # 提取IP类别,http或者https ip_sum = 100 # IP池总数 def __init__(self,key,neek,ip_sum = 100,ttl = 60): self.key = key self.neek = neek self.ttl = ttl self.ip_sum = ip_sum self._init() # init the proxy def _init(self): print('初始化中...') if os.path.exists(self.pool_path): with open(self.pool_path,'r') as f: self.ip_pool = json.loads(f.read()) response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8') address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1) # add ip_white url = 'http://web.http.cnapi.cc/index/index/save_white?neek={neek}&appkey={key}&white={local}'.format( neek=self.neek, key=self.key, local=address) response = requests.get(url=url) code = json.loads(response.text).get('code') if code == 0 or code == 115: print('初始化成功,启动中稍等..') else: print('初始化芝麻账号失败') time.sleep(2) def check_ip(self): for index,node in enumerate(self.ip_pool): ip = node[0] port = node[1] expire_time = node[2] if expire_time - self.ttl < time.time(): del self.ip_pool[index] print('IP即将超时,已删除',ip) if not self.checkproxy(ip + ':' + port,ip): del self.ip_pool[index] # 删除 print('使用IP代理请求出错,删除',ip) while len(self.ip_pool) < self.ip_sum: if self.pack == 0: self.add_ip_count() else: self.add_ip() time.sleep(2) # 不能请求太快 self.save_to_file() # 存到json文件 # 根据套餐提取 def add_ip(self, num=20): port = '11' if self.ip_type == 'https' else '1' # http(default) & https get_url = 'http://webapi.http.zhimacangku.com/getip?num={num}&type=2&pro=&city=0&yys=0&port={port}&pack={pack}&ts=1&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='.format(port=port,num=num,pack=self.pack) response = requests.get(get_url) # code = json.loads(response.text).get('code') self.parse(response.text) # 按次提取IP num:每次提取数量,invalid:有效时长 TODO 这里可以修改为其他 def add_ip_count(self, num=20, invalid_time=2): port = '11' if self.ip_type == 'https' else '1' # http(default) & https get_url = 'http://webapi.http.zhimacangku.com/getip?num={num}&type=2&pro=&city=0&yys=0&port={port}&time={invalid_time}&ts=1&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='.format(num=num,invalid_time=invalid_time,port=port) response = requests.get(get_url) self.parse(response.text) # 解析提取的IP def parse(self, json_data): count = 0 ret_dict = json.loads(json_data) if ret_dict.get('success'): nodes = ret_dict.get('data') for node in nodes: expire_time = self.str_to_time(node.get('expire_time')) if expire_time - self.ttl < time.time(): print('该IP存活时间过短,已弃用',node.get('ip')) continue tmp = [[str(node.get('ip')),str(node.get('port')),expire_time,self.ip_type]] self.ip_pool.extend(tmp) # 添加到ip池 count += 1 print('本次获取' + str(count) + '个IP') # 时间字符串转时间戳 def str_to_time(self, time_str): # 先转换为时间数组 timeArray = time.strptime(time_str, "%Y-%m-%d %H:%M:%S") # 转换为时间戳 timeStamp = int(time.mktime(timeArray)) return timeStamp # 检查代理IP有效性 def checkproxy(self,proxy,ip): return True # response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8',proxies={self.ip_type:proxy}) # address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1) # time.sleep(2) # return str(address) == str(ip) def save_to_file(self): with open(self.pool_path, 'w') as f: f.write(json.dumps(self.ip_pool)) # 使用方法 while True: try: begin = time.time() * 1000 zm = ZhiMaPool('You App Key', 'Your Neek') zm.ip_sum = 50 # IP池总数量 # zm.pack = 121888 # 套餐pack参数,为0则使用按次提取,默认为0 # zm.ip_type = 'http' # http or https # zm.ttl = 60 # 过期提前失效时间,默认提前60秒 # zm.pool_path = './zhima_pool.json' # IP池保存路径 zm.check_ip() cost = time.time() * 1000 - begin print('本次耗时'+ str(cost) + '毫秒') time.sleep(30) # 间隔时间请少于ttl时长 except Exception as e: print(e) 后台运行nohup python3 ZhiMaProxy.py >/dev/null 2>log & 即可在同目录下的zhima_pool.json文件得到一个健康的IP池重复一遍,获取IP不收费,使用才收费
Python使用芝麻代理维护一个健康可用的IP池 最近有个需求要用Python做一个爬虫不间断运行,但是对方网站做了比较严格的反爬,然后就选择了用随机header和代理。刚开始的时候使用的免费代理,后来发现免费才是最贵的,经常失效或者连接不上,于是改为使用付费代理,最后选择了芝麻代理但是爬虫每秒请求可能为5QPS左右,芝麻代理默认请求为1QPS,所以只能采取维护一个代理池的方式,每次请求从中随机选取。刚开始的时候使用的是购买套餐,后来发现并不划算,套餐每天有使用上限,IP存活时间长的,上限数量就低,IP上限高的,存活时间又比较低,有预算上限的长时间爬虫类项目可以选择IP存活时间长的套餐,把维护IP池数量稍微降低一点,勉强够用一天了。不过后期还是建议使用按次购买,控制好频率就不怕超限。注意IP获取不计次,但是一旦使用就会计次之前没经验选择5分钟套餐,不到两点IP用量就要到上限了,选套餐还是建议存活时间长的这个维护IP池同时支持套餐和按次收费,所以也不用太过纠结首先你要获取到你的AppKey和Neek参数,在官网提取IP生成的API链接里可以获取到http://h.zhimaruanjian.com/getapi/#obtain_ip如果是选择的用套餐提取,还会有对应的pack参数,是你自己的对应套餐ID,在上面的链接同样可以获取到,然后实例化时把参数填进去即可。pack为0则按次提取IP这里我们按照维护大小为50个的IP池为例,使用示例如下:while True: try: begin = time.time() * 1000 zm = ZhiMaPool('You App Key', 'Your Neek') # 你的AppKey的Neek参数 zm.ip_sum = 50 # IP池总数量 # zm.pack = 121888 # 套餐pack参数,为0则使用按次提取,默认为0 # zm.ip_type = 'http' # http or https # zm.ttl = 60 # 过期提前失效时间,默认提前60秒 # zm.pool_path = './zhima_pool.json' # IP池保存路径 zm.check_ip() cost = time.time() * 1000 - begin print('本次耗时'+ str(cost) + '毫秒') time.sleep(30) # 间隔时间请少于ttl时长 except Exception as e: print(e)完整代码# -*- coding: utf-8 -*- # __author__ = "Yuuuu" gty0211@foxmail.com # Date: 2020-10-22 Python: 3.8 import os import time import requests import json import re class ZhiMaPool(object): pool_path = './zhima_pool.json' # IP池保存地址 ttl = 60 # 过期间隔 pack = 0 # 套餐pack参数,为0则使用按次提取 ip_pool = [] ip_type = 'http' # 提取IP类别,http或者https ip_sum = 100 # IP池总数 def __init__(self,key,neek,ip_sum = 100,ttl = 60): self.key = key self.neek = neek self.ttl = ttl self.ip_sum = ip_sum self._init() # init the proxy def _init(self): print('初始化中...') if os.path.exists(self.pool_path): with open(self.pool_path,'r') as f: self.ip_pool = json.loads(f.read()) response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8') address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1) # add ip_white url = 'http://web.http.cnapi.cc/index/index/save_white?neek={neek}&appkey={key}&white={local}'.format( neek=self.neek, key=self.key, local=address) response = requests.get(url=url) code = json.loads(response.text).get('code') if code == 0 or code == 115: print('初始化成功,启动中稍等..') else: print('初始化芝麻账号失败') time.sleep(2) def check_ip(self): for index,node in enumerate(self.ip_pool): ip = node[0] port = node[1] expire_time = node[2] if expire_time - self.ttl < time.time(): del self.ip_pool[index] print('IP即将超时,已删除',ip) if not self.checkproxy(ip + ':' + port,ip): del self.ip_pool[index] # 删除 print('使用IP代理请求出错,删除',ip) while len(self.ip_pool) < self.ip_sum: if self.pack == 0: self.add_ip_count() else: self.add_ip() time.sleep(2) # 不能请求太快 self.save_to_file() # 存到json文件 # 根据套餐提取 def add_ip(self, num=20): port = '11' if self.ip_type == 'https' else '1' # http(default) & https get_url = 'http://webapi.http.zhimacangku.com/getip?num={num}&type=2&pro=&city=0&yys=0&port={port}&pack={pack}&ts=1&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='.format(port=port,num=num,pack=self.pack) response = requests.get(get_url) # code = json.loads(response.text).get('code') self.parse(response.text) # 按次提取IP num:每次提取数量,invalid:有效时长 TODO 这里可以修改为其他 def add_ip_count(self, num=20, invalid_time=2): port = '11' if self.ip_type == 'https' else '1' # http(default) & https get_url = 'http://webapi.http.zhimacangku.com/getip?num={num}&type=2&pro=&city=0&yys=0&port={port}&time={invalid_time}&ts=1&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='.format(num=num,invalid_time=invalid_time,port=port) response = requests.get(get_url) self.parse(response.text) # 解析提取的IP def parse(self, json_data): count = 0 ret_dict = json.loads(json_data) if ret_dict.get('success'): nodes = ret_dict.get('data') for node in nodes: expire_time = self.str_to_time(node.get('expire_time')) if expire_time - self.ttl < time.time(): print('该IP存活时间过短,已弃用',node.get('ip')) continue tmp = [[str(node.get('ip')),str(node.get('port')),expire_time,self.ip_type]] self.ip_pool.extend(tmp) # 添加到ip池 count += 1 print('本次获取' + str(count) + '个IP') # 时间字符串转时间戳 def str_to_time(self, time_str): # 先转换为时间数组 timeArray = time.strptime(time_str, "%Y-%m-%d %H:%M:%S") # 转换为时间戳 timeStamp = int(time.mktime(timeArray)) return timeStamp # 检查代理IP有效性 def checkproxy(self,proxy,ip): return True # response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8',proxies={self.ip_type:proxy}) # address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1) # time.sleep(2) # return str(address) == str(ip) def save_to_file(self): with open(self.pool_path, 'w') as f: f.write(json.dumps(self.ip_pool)) # 使用方法 while True: try: begin = time.time() * 1000 zm = ZhiMaPool('You App Key', 'Your Neek') zm.ip_sum = 50 # IP池总数量 # zm.pack = 121888 # 套餐pack参数,为0则使用按次提取,默认为0 # zm.ip_type = 'http' # http or https # zm.ttl = 60 # 过期提前失效时间,默认提前60秒 # zm.pool_path = './zhima_pool.json' # IP池保存路径 zm.check_ip() cost = time.time() * 1000 - begin print('本次耗时'+ str(cost) + '毫秒') time.sleep(30) # 间隔时间请少于ttl时长 except Exception as e: print(e) 后台运行nohup python3 ZhiMaProxy.py >/dev/null 2>log & 即可在同目录下的zhima_pool.json文件得到一个健康的IP池重复一遍,获取IP不收费,使用才收费 -
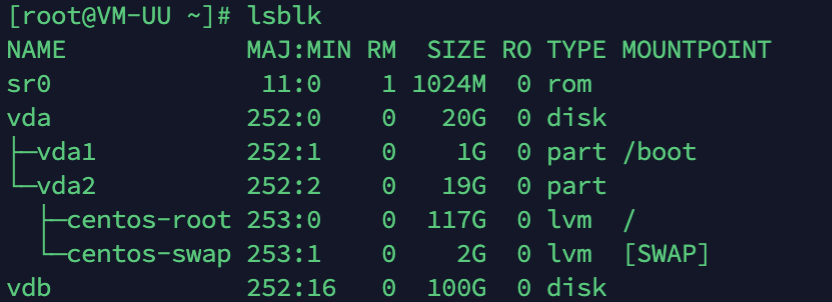
![Centos添加新硬盘扩容根目录]() Centos添加新硬盘扩容根目录 云服务器新挂载了一块硬盘,还没分区,想要直接扩容到根目录,想要做到无缝扩容。进入系统查看,新硬盘名称是vdb,100G的lsblk然后我们通过LVM,逻辑卷管理的方式挂载到vda上面这里引用下别人的介绍LVM简单介绍: 它是 Linux 下对磁盘分区进行管理的一种机制。LVM 是建立在磁盘分区和文件系统之间的一个逻辑层,系统管理员可以利用 LVM 在不重新对磁盘分区的情况下动态的调整分区的大小。如果系统新增了一块硬盘,通过 LVM 就可以将新增的硬盘空间直接扩展到原来的磁盘分区上。 通过 LVM 技术,可以屏蔽掉磁盘分区的底层差异,在逻辑上给文件系统提供了一个卷的概念,然后在这些卷上建立相应的文件系统。下面是 LVM 中主要涉及的一些概念。 物理存储设备(Physical Media):指系统的存储设备文件,比如 /dev/sda、/dev/sdb 等。 PV(物理卷 Physical Volume):指硬盘分区或者从逻辑上看起来和硬盘分区类似的设备(比如 RAID 设备)。 VG(卷组 Volume Group):类似于非 LVM 系统中的物理硬盘,一个 LVM 卷组由一个或者多个 PV(物理卷)组成。 LV(逻辑卷 Logical Volume):类似于非 LVM 系统上的磁盘分区,LV 建立在 VG 上,可以在 LV 上建立文件系统。 PE(Physical Extent):PV(物理卷)中可以分配的最小存储单元称为 PE,PE 的大小是可以指定的。 LE(Logical Extent):LV(逻辑卷)中可以分配的最小存储单元称为 LE,在同一个卷组中,LE 的大小和 PE 的大小是一样的,并且一一对应。 可以这么理解,LVM 是把硬盘的分区分成了更小的单位(PE),再用这些单元拼成更大的看上去像分区的东西(PV),进而用 PV 拼成看上去像硬盘的东西(VG),最后在这个新的硬盘上创建分区(LV)。文件系统则建立在 LV 之上,这样就在物理硬盘和文件系统中间添加了一层抽象(LVM)。下图大致描述了这些概念之间的关系: 对上图中的结构做个简单的介绍: 两块物理硬盘 A 和 B 组成了 LVM 的底层结构,这两块硬盘的大小、型号可以不同。PV 可以看做是硬盘上的分区,因此可以说物理硬盘 A 划分了两个分区,物理硬盘 B 划分了三个分区。然后将前三个 PV 组成一个卷组 VG1,后两个 PV 组成一个卷组 VG2。接着在卷组 VG1 上划分了两个逻辑卷 LV1 和 LV2,在卷组 VG2 上划分了一个逻辑卷 LV3。最后,在逻辑卷 LV1、LV2 和 LV3 上创建文件系统,分别挂载在 /usr、/home 和 /var 目录。1.建立新分区使用 fdisk -l 命令查看:可以看到 /dev/vdb 是新增的硬盘。执行 fdisk /dev/vdb 对 vdb 进行分区。输入 n 建立新分区,接着输入 p 选择主分区,分区号和扇区号直接回车默认即可,这样会将整个硬盘都添加到新分区中。先不要退出,接下来更改分区文件系统id,输入t之后更改分区文件系统id,输入L查看所有列表,最后我们输入8e,修改为LVM格式,最后w把更改写入硬盘。再次查看这时已经有了一个新的分区 vdb12.创建物理卷pv创建物理卷 pvcreate /dev/vdb1pvdisplay查看,已经提示我们有一个新增的 /dev/vdb13.扩容卷组vgvgdisplay 查看卷组 可以看到原有卷组名称为 centos将新创建的 物理卷pv /dev/vdb1 追加到原有卷组里,也就是 "centos" 中,扩容卷组。vgextend centos /dev/vdb1然后再次查看,发现总容量已经由原来的20G增加到了120G,VG卷组扩容成功4.逻辑卷扩容lvdisplay 查看当前逻辑卷,可以看到根目录逻辑卷的路径为 /dev/centos/root把我们新增的vdb1逻辑卷全部扩容进去 lvextend -l+100%FREE /dev/centos/root 5.最后扩容文件系统xfs_growfs /dev/centos/root可以看到已经扩容完成了
Centos添加新硬盘扩容根目录 云服务器新挂载了一块硬盘,还没分区,想要直接扩容到根目录,想要做到无缝扩容。进入系统查看,新硬盘名称是vdb,100G的lsblk然后我们通过LVM,逻辑卷管理的方式挂载到vda上面这里引用下别人的介绍LVM简单介绍: 它是 Linux 下对磁盘分区进行管理的一种机制。LVM 是建立在磁盘分区和文件系统之间的一个逻辑层,系统管理员可以利用 LVM 在不重新对磁盘分区的情况下动态的调整分区的大小。如果系统新增了一块硬盘,通过 LVM 就可以将新增的硬盘空间直接扩展到原来的磁盘分区上。 通过 LVM 技术,可以屏蔽掉磁盘分区的底层差异,在逻辑上给文件系统提供了一个卷的概念,然后在这些卷上建立相应的文件系统。下面是 LVM 中主要涉及的一些概念。 物理存储设备(Physical Media):指系统的存储设备文件,比如 /dev/sda、/dev/sdb 等。 PV(物理卷 Physical Volume):指硬盘分区或者从逻辑上看起来和硬盘分区类似的设备(比如 RAID 设备)。 VG(卷组 Volume Group):类似于非 LVM 系统中的物理硬盘,一个 LVM 卷组由一个或者多个 PV(物理卷)组成。 LV(逻辑卷 Logical Volume):类似于非 LVM 系统上的磁盘分区,LV 建立在 VG 上,可以在 LV 上建立文件系统。 PE(Physical Extent):PV(物理卷)中可以分配的最小存储单元称为 PE,PE 的大小是可以指定的。 LE(Logical Extent):LV(逻辑卷)中可以分配的最小存储单元称为 LE,在同一个卷组中,LE 的大小和 PE 的大小是一样的,并且一一对应。 可以这么理解,LVM 是把硬盘的分区分成了更小的单位(PE),再用这些单元拼成更大的看上去像分区的东西(PV),进而用 PV 拼成看上去像硬盘的东西(VG),最后在这个新的硬盘上创建分区(LV)。文件系统则建立在 LV 之上,这样就在物理硬盘和文件系统中间添加了一层抽象(LVM)。下图大致描述了这些概念之间的关系: 对上图中的结构做个简单的介绍: 两块物理硬盘 A 和 B 组成了 LVM 的底层结构,这两块硬盘的大小、型号可以不同。PV 可以看做是硬盘上的分区,因此可以说物理硬盘 A 划分了两个分区,物理硬盘 B 划分了三个分区。然后将前三个 PV 组成一个卷组 VG1,后两个 PV 组成一个卷组 VG2。接着在卷组 VG1 上划分了两个逻辑卷 LV1 和 LV2,在卷组 VG2 上划分了一个逻辑卷 LV3。最后,在逻辑卷 LV1、LV2 和 LV3 上创建文件系统,分别挂载在 /usr、/home 和 /var 目录。1.建立新分区使用 fdisk -l 命令查看:可以看到 /dev/vdb 是新增的硬盘。执行 fdisk /dev/vdb 对 vdb 进行分区。输入 n 建立新分区,接着输入 p 选择主分区,分区号和扇区号直接回车默认即可,这样会将整个硬盘都添加到新分区中。先不要退出,接下来更改分区文件系统id,输入t之后更改分区文件系统id,输入L查看所有列表,最后我们输入8e,修改为LVM格式,最后w把更改写入硬盘。再次查看这时已经有了一个新的分区 vdb12.创建物理卷pv创建物理卷 pvcreate /dev/vdb1pvdisplay查看,已经提示我们有一个新增的 /dev/vdb13.扩容卷组vgvgdisplay 查看卷组 可以看到原有卷组名称为 centos将新创建的 物理卷pv /dev/vdb1 追加到原有卷组里,也就是 "centos" 中,扩容卷组。vgextend centos /dev/vdb1然后再次查看,发现总容量已经由原来的20G增加到了120G,VG卷组扩容成功4.逻辑卷扩容lvdisplay 查看当前逻辑卷,可以看到根目录逻辑卷的路径为 /dev/centos/root把我们新增的vdb1逻辑卷全部扩容进去 lvextend -l+100%FREE /dev/centos/root 5.最后扩容文件系统xfs_growfs /dev/centos/root可以看到已经扩容完成了 -
![PHP使用mkdir创建目录后无法写入问题]()
-
![网页快照几种实现方案参考]() 网页快照几种实现方案参考 (一)、HTML转图片1.使用 html2canvas 制作网页快照(1)介绍官网: https://html2canvas.hertzen.com/Html2canvas是一个JS库,通过在web引入JS的方式,点击按钮后可以根据ID呼叫需要制作快照的标签,会根据标签制作成图片。(2)使用方法如需要制作快照的html为:<div id="capture" style="padding: 10px; background: #f5da55"> <h4 style="color: #000; ">Hello world!</h4></div>那么使用html2canvas 制作快照只需要html2canvas(document.querySelector("#capture")).then(canvas => { document.body.appendChild(canvas)});(3)特征其支援的WebBrowser包含Firefox 3.5+Google ChromeOpera 12+IE9+Safari 6+优点:支援的WebBrowser较多,使用比较方便,只需要引入一个JS即可缺点:需要根据ID制作快照2.使用wkhtmltoimage 制作网页快照(1)介绍官网:https://wkhtmltopdf.org/wkhtmltoimage是一个独立的程序,和wkhtmltopdf属于同一个程序中,支援Windows、Ubuntu、Centos、Debian、MacOS等主流操作系统,安装完毕之后使用十分方便,只需要一个url即可制作成快照图片或者pdf。(2)使用方法使用简单,只需要一个可以访问的url即可wkhtmltoimage http://openclever.pro/OpenRich/admin/login.aspx login.pngWkhtmltoimage [要制作快照的url] [输出档的路径]完整中文参数详解在:https://note.coccoo.cc/Archive/wkhtmltopdforimage_params_zh.html(3)特征优点:使用十分方便,支援的操作系统较多缺点:需要使用可以直接访问的url(如果需要登陆的页面可能无法拍快照)3.使用WebSiteThumbnail制作网页快照(C#)(1)介绍使用WebSiteThumbnail.cs制作网页快照,把这个class放入C#项目中,然后直接呼叫GetWebSiteThumbnail这个Function就可以制作快照图片。WebSiteThumb.cs下载(2)使用方法 //在任意网页中的Page_Load事件时,加入如下代码: protected void Page_Load(object sender, EventArgs e) { Bitmap m_Bitmap = WebSiteThumbnail.GetWebSiteThumbnail("http://www.google.cn", 600, 600, 600, 600); MemoryStream ms = new MemoryStream(); m_Bitmap.Save(ms, System.Drawing.Imaging.ImageFormat.Png);//JPG、GIF、PNG等均可 byte[] buff = ms.ToArray(); Response.BinaryWrite(buff); }(3)特征优点:C#语言,可以融入项目中缺点:没来得及测试,暂不清楚效果如何(二)、存储当前网页的Coding版本渲染1.使用保存Html源码的形式制作快照(1)介绍把整个html的源代码(包含所有html、js和css)保存下来,类似于在浏览器中Ctrl+S存储为 .html 的档案,命名为 文件名-版本号.html,如 detail-26018.html,这样只需要记录版本号 26018 就可以找到对应的文件名称,直接展示即可作为快照使用。(2)使用方法把渲染出来的画面直接保存为 xxx-version.html ,需要查看快照的时候直接展示在浏览器即可。(3)特征优点:便于存储和管理,可以还原成页面原本的样子缺点:存储大量档可能会导致服务器缓慢,可以不存在DB而是存于io中,DB直接保存io的位置即可
网页快照几种实现方案参考 (一)、HTML转图片1.使用 html2canvas 制作网页快照(1)介绍官网: https://html2canvas.hertzen.com/Html2canvas是一个JS库,通过在web引入JS的方式,点击按钮后可以根据ID呼叫需要制作快照的标签,会根据标签制作成图片。(2)使用方法如需要制作快照的html为:<div id="capture" style="padding: 10px; background: #f5da55"> <h4 style="color: #000; ">Hello world!</h4></div>那么使用html2canvas 制作快照只需要html2canvas(document.querySelector("#capture")).then(canvas => { document.body.appendChild(canvas)});(3)特征其支援的WebBrowser包含Firefox 3.5+Google ChromeOpera 12+IE9+Safari 6+优点:支援的WebBrowser较多,使用比较方便,只需要引入一个JS即可缺点:需要根据ID制作快照2.使用wkhtmltoimage 制作网页快照(1)介绍官网:https://wkhtmltopdf.org/wkhtmltoimage是一个独立的程序,和wkhtmltopdf属于同一个程序中,支援Windows、Ubuntu、Centos、Debian、MacOS等主流操作系统,安装完毕之后使用十分方便,只需要一个url即可制作成快照图片或者pdf。(2)使用方法使用简单,只需要一个可以访问的url即可wkhtmltoimage http://openclever.pro/OpenRich/admin/login.aspx login.pngWkhtmltoimage [要制作快照的url] [输出档的路径]完整中文参数详解在:https://note.coccoo.cc/Archive/wkhtmltopdforimage_params_zh.html(3)特征优点:使用十分方便,支援的操作系统较多缺点:需要使用可以直接访问的url(如果需要登陆的页面可能无法拍快照)3.使用WebSiteThumbnail制作网页快照(C#)(1)介绍使用WebSiteThumbnail.cs制作网页快照,把这个class放入C#项目中,然后直接呼叫GetWebSiteThumbnail这个Function就可以制作快照图片。WebSiteThumb.cs下载(2)使用方法 //在任意网页中的Page_Load事件时,加入如下代码: protected void Page_Load(object sender, EventArgs e) { Bitmap m_Bitmap = WebSiteThumbnail.GetWebSiteThumbnail("http://www.google.cn", 600, 600, 600, 600); MemoryStream ms = new MemoryStream(); m_Bitmap.Save(ms, System.Drawing.Imaging.ImageFormat.Png);//JPG、GIF、PNG等均可 byte[] buff = ms.ToArray(); Response.BinaryWrite(buff); }(3)特征优点:C#语言,可以融入项目中缺点:没来得及测试,暂不清楚效果如何(二)、存储当前网页的Coding版本渲染1.使用保存Html源码的形式制作快照(1)介绍把整个html的源代码(包含所有html、js和css)保存下来,类似于在浏览器中Ctrl+S存储为 .html 的档案,命名为 文件名-版本号.html,如 detail-26018.html,这样只需要记录版本号 26018 就可以找到对应的文件名称,直接展示即可作为快照使用。(2)使用方法把渲染出来的画面直接保存为 xxx-version.html ,需要查看快照的时候直接展示在浏览器即可。(3)特征优点:便于存储和管理,可以还原成页面原本的样子缺点:存储大量档可能会导致服务器缓慢,可以不存在DB而是存于io中,DB直接保存io的位置即可